While the headlines are dominated by massive 100GW data centers and the “War for Watts,” I’ve been investigating a parallel, perhaps more disruptive, frontier: The Edge.
If the giant cloud clusters are the “Blue Whales” of the AI era—massive, powerful, but energy-heavy—then Small Language Models (SLMs) and Edge AI are the “Insects.” They are lightweight, highly specialized, and capable of surviving in resource-constrained environments where the giants would starve.
Here is my synthesis of why “Small” is the new “Big,” and why I’ve shifted my research toward the decentralized metabolism of intelligence.
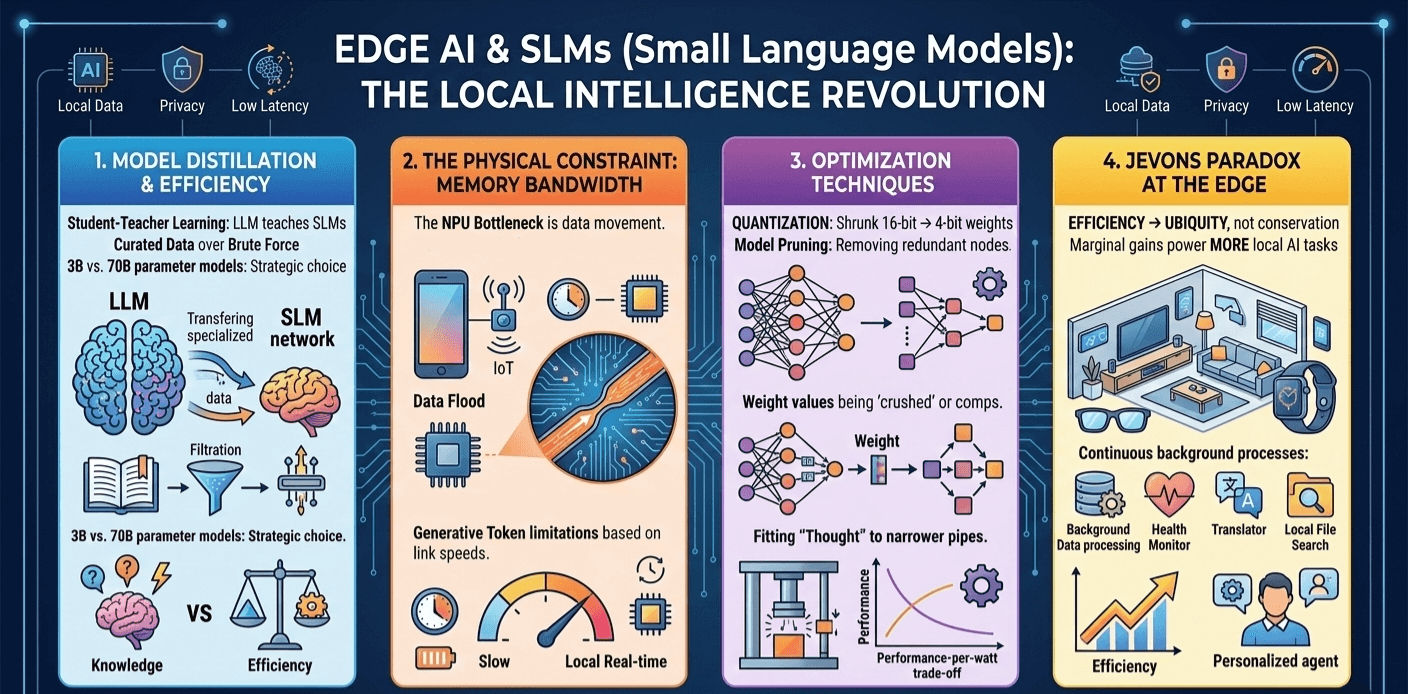
1. The Architecture of “Quality over Quantity”
The old dogma was that intelligence is strictly a function of scale: more parameters equals more “smart.” My research into Model Distillation has proven this wrong.
We are seeing a “Student-Teacher” revolution. Large “Teacher” models (the LLMs) are being used to train “Student” models (SLMs). By filtering out the “noise” of the internet and training on “textbook-quality” curated data, a 3B parameter model can now outperform a 70B parameter model from just a year ago.
We are moving from “Brute Force Learning” to “Curated Understanding.” In the physical world, this is the difference between an engine that burns 100 gallons of fuel to move a mile and a highly tuned electric motor that does the same with a fraction of the energy.
2. The Memory Bandwidth Wall: A New Physical Constraint
I had to look past the NPU (Neural Processing Unit) hype. The real bottleneck for Edge AI isn’t raw compute; it’s Memory Bandwidth.
In a massive data center, GPUs have TB/s of bandwidth. Your smartphone has roughly 50-90 GB/s. Because every “token” the AI generates requires the system to read the entire weight of the model, the “speed” of your on-device AI is literally limited by the speed of the copper traces on your motherboard.
This has forced a radical shift in engineering:
- Quantization: We are shrinking 16-bit weights down to 4-bit or even 1.5-bit.
- The Physics: This isn’t just a software trick; it’s a way to fit the “thought” into the narrow physical pipe of the hardware. It’s the digital equivalent of high-pressure hydraulics—forcing more “work” through a smaller opening.
3. The Philosophy of the “Local Agent” vs. “The Oracle”
There is a profound philosophical shift happening here.
- The Cloud LLM is an “Oracle”: You travel to it (via the internet), ask a question, and wait for a response from the “God in the Machine.”
- The Edge SLM is an “Agent”: It lives with you. It is “Ambient Intelligence.”
By moving the metabolism of AI to the edge, we achieve Local Autonomy. Your data never leaves the device, which solves the privacy paradox, and the latency drops to zero. This is the difference between a central government making every decision and a decentralized community of autonomous individuals.
4. Jevons Paradox at the Edge
I previously mentioned the Jevons Paradox in the context of power grids, but it applies to your pocket, too.
As we make SLMs more efficient, we don’t save battery life. Instead, we use that “saved” energy to run more AI tasks in the background—real-time translation, continuous health monitoring, and proactive scheduling.
Efficiency doesn’t lead to conservation; it leads to ubiquity. We aren’t going to have “less AI”; we are going to have AI in our glasses, our watches, and our tools, all consuming the marginal efficiency gains as fast as we can invent them.
5. Reorganizing the Value Chain: Where the Energy Goes
If the Cloud is about Generation, the Edge is about Context.
| Layer | Physical Reality | Intellectual Output |
|---|---|---|
| Cloud (The Giant) | Liquid Cooling, Nuclear PPAs | General Reason, Scientific Discovery |
| Edge (The Small) | Thermal Throttling, Battery Cycles | Actionable Insight, Personal Privacy |
The Takeaway
The “Atoms vs. Bits” war is being fought on two fronts. While the giants fight for the power grid, the innovators are fighting for the Thermal Envelope of your handheld devices.
If a model triggers “thermal throttling” (slowing down to avoid melting), it has failed its physical test. The future belongs to those who can squeeze the most “logic” into a device without it becoming too hot to hold.