TL;DR: Run a hybrid design — a tiny, deterministic Rust “runner” on the Pi for low-latency GPIO / relay work, and treat a GitOps GitHub-backed orchestrator as your reflective brain for evolving logic and heavy planning. Use ephemeral containers, scoped secrets, and human-in-the-loop PR gates for any capability that can change code or touch money.
Why this matters (context & evidence)
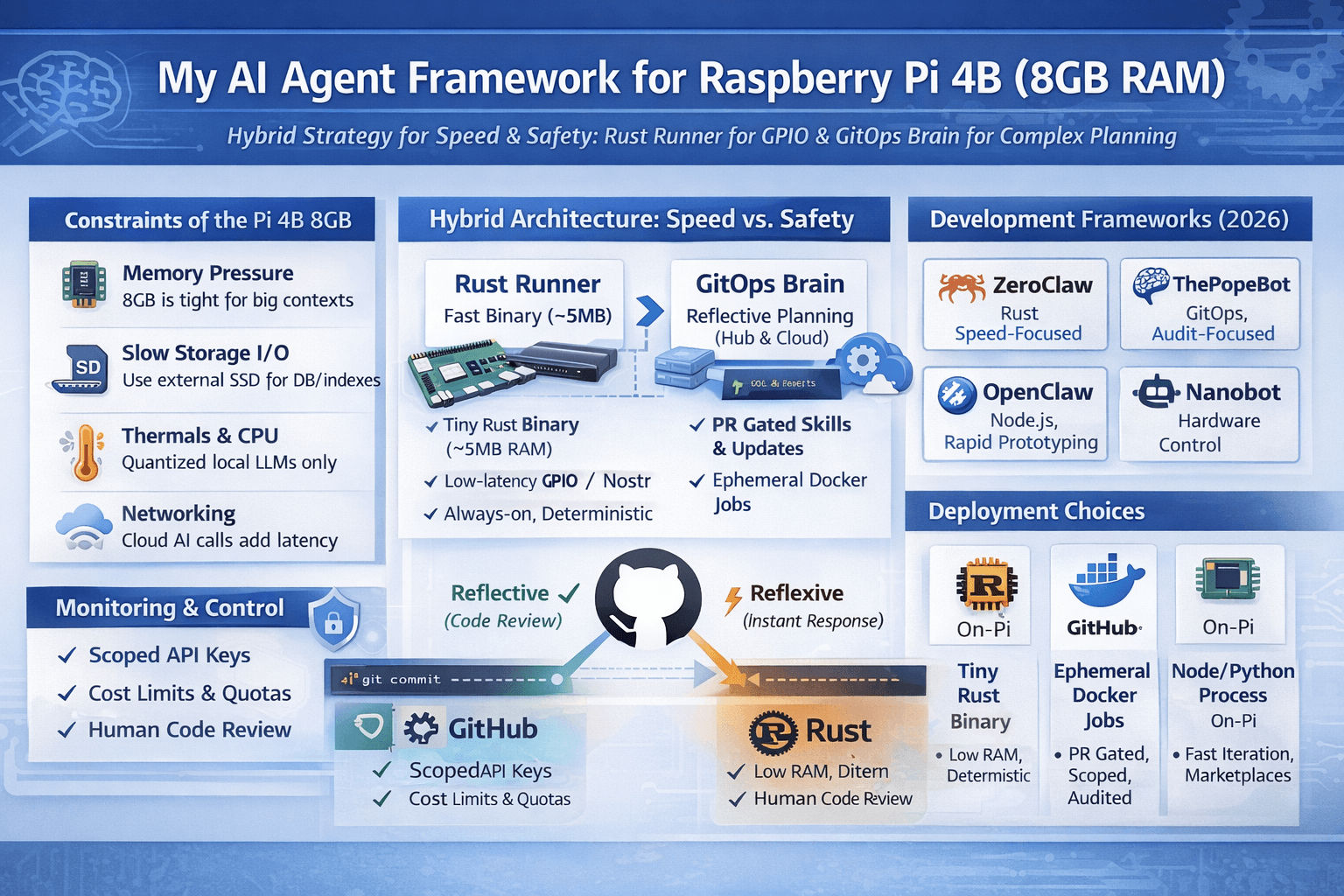
I built kheAI to be useful and survivable: useful means it must act autonomously; survivable means it must not silently burn cash, leak credentials, or rewrite its own safety rules. I based the architecture around the GitOps idea implemented in PopeBot — the repository is the agent’s long-term memory and PRs are the safety gate.
Hardware baseline for this discussion: the Raspberry Pi 4 Model B with 8 GB of RAM — that’s the official 8 GB Pi spec and the environment I tested for kheAI.
The 2026 landscape — quick, actionable classification
The market has consolidated into two practical camps:
- Convenience SaaS — managed platforms with strong UX, ML scaling, and ready integrations. Great for speed; harsh for auditability and privacy. Example vendor patterns: consumption or per-seat pricing, enterprise lock-in, and opaque internal logs. (See current Agentforce and managed operator offerings.)
- Orchestration / Self-hosted frameworks — you own the plumbing, logs, and cost. You trade engineering work for control. Examples include agent frameworks and model orchestration layers such as LangChain/LangSmith for observability and local runtimes for privacy.
Notes on pricing & vendors: managed enterprise platforms (Salesforce Agentforce, Beam.ai, etc.) typically use consumption or per-seat models and are often priced as custom/enterprise at scale; they are convenient but can balloon your recurring cost and hide “thought” traces that you need for compliance.
Commercial Platforms (Managed Services)
| Platform | Target Audience | Pricing (Estimated) | The Catch |
|---|---|---|---|
| Salesforce Agentforce | Enterprise CRM | ~$550/user·mo | Total ecosystem lock-in. Data is trapped in the Salesforce “Trust Layer.” |
| OpenAI Operator | General Consumers | Included in Pro (~$200/mo) | No self-hosted audit logs; limited “system” access. High latency for local triggers; zero “Local-First” privacy. |
| Beam.ai | Fortune 500 Ops | Enterprise (Custom) | Powerful, but a “black box” for process automation. Fantastic UI, but you can’t audit the underlying “thought” traces. |
| Lindy / Noimos | SMB / Marketing | 500/mo | No-code ease, but limited developer extensibility. Easy “Vibe Coding,” but limited API-to-Hardware hooks. |
Development Frameworks (Self-Hosted)
While LangChain and CrewAI remain the “corporate” standards for Python-heavy environments, 2026 has seen the rise of MCP-native frameworks. These allow agents to swap “tools” (databases, local files, hardware pins) without rewriting the core engine.
- LangChain / LangSmith: The industry standard for observability, but can be heavy for edge devices.
- CrewAI: The best for multi-agent “roleplay,” but lacks a native “governance” layer.
- Semantic Kernel / AutoGen: Microsoft’s heavy hitters. They are robust but often lack the Git-native auditability I need for professional operations.
- PopeBot: Emerged as the GitOps-native agents because it treats the Git History as the Agent’s Long-Term Memory. If an agent makes a mistake, you don’t just “debug” it—you
git revertits personality. My niche choice. It treats every action as a commit, turning a repository into a permanent audit trail.
Pi 4B (8GB) — real constraints and operational realities
When you say “run an agent on a Pi,” you mean more than models and FLOPs. On an 8GB Pi the hard limits are:
- Memory pressure — 8 GB is small for long lived Node or Python processes with heavy context windows, vector stores, or embeddings caching. Context bloat + memory leaks = crashes.
- Storage I/O — SD cards are slow and wear out fast. Put database and swap onto an external NVMe/SSD via USB 3.0 whenever possible.
- Thermals & CPU — sustained CPU load throttles; avoid sustained heavy model inference on the Pi unless using quantized, tiny models.
- Networking & latency — cloud model calls are network-bound; design for asynchronous retries and local timeouts.
Practical Pi tuning I used:
- Use zram and a small swap file (not on SD if you can avoid it).
- Attach an external SSD for SQLite and vector indexes.
- Limit container memory with Docker
--memoryflags and use ephemeral containers for untrusted work. - Use a process supervisor (systemd) that will restart deterministic binaries, not developer daemons.
Candidate runtime patterns (what I experimented with)
Below are practical runtime archetypes, and whether they fit an 8GB Pi.
A — Tiny native runtime (Rust / static binary)
- Pros: ultra low RAM, deterministic, secure by default, ideal for GPIO and relay tasks.
- Cons: not designed for heavy, creative LLM work on device; logic updates require CI/CD flow.
- When to use: real-time sensor processing, always-on background tasks, and any code you want “set-and-forget.”
Implementation note: build your small runner as a single, memory-bounded binary that polls or subscribes to a message queue (MQTT/Nostr) and applies small, auditable rules.
B — Ephemeral Docker Jobs (GitOps orchestrator)
- Pros: run untrusted skills in isolated containers, enforce resource limits, and keep a full audit trail if you use a repo-as-memory pattern. This is the PopeBot model: event handler creates a branch/PR; workers execute tasks as jobs; human merges grant capability.
- Cons: job cold starts and added latency; requires GitHub (or comparable) infra.
C — Resident Node/Python agent (real-time, rich ecosystem)
- Pros: fastest iteration, massive ecosystem (npm/pypi) and marketplaces of skills.
- Cons: Node.js and long-running Python processes are prone to memory leaks and context bloat on constrained devices; require daily restarts or aggressive memory controls.
D — Local quantized LLM inference (tiny model runners)
- Pros: privacy and zero API spend; Ollama-style local runtimes let you run small models on device. Use for private classification/summarization tasks only.
- Cons: model quality and context window are limited; still costly for complex code generation or planning.
The Contenders for the Pi
- OpenClaw (The “Vibe” Choice): The darling of the “vibe coding” JS/TS ecosystem. Perfect for rapid prototyping. Its ClawHub marketplace is the “App Store” for agent skills. However, it suffers heavily from context bloat. Left running 24/7 on a Pi, Node.js memory leaks will eventually crash it.
- ZeroClaw (The “Rust” Kernel): Written 100% in Rust. It’s an 8.8MB static binary that idles in <5MB of RAM. It avoids massive external Vector DBs by using a local SQLite hybrid search. It is highly secure, deterministic, and purpose-built for high-density edge deployments.
- Nanobot (NanoLLM): The “Hardware King.” If you need to flash a physical lamp or trigger a GPIO pin when you get a Bitcoin tip, this is the one. It’s a “neural compiler” for hardware.
- The Pope Bot: Built on a two-layer Docker model. Instead of keeping a massive process running in memory, it executes tasks as ephemeral Docker “Jobs.” By spinning up a container for a task and killing it immediately after, it ensures that a memory leak in a tool doesn’t crash another tool.
Comparison: The Audit vs. The Action
| Feature | ZeroClaw 🦀 | The PopeBot 🧠 | OpenClaw 🌐 | Nanobot 🤖 |
|---|---|---|---|---|
| Core Logic | Native binary (Hardened Edge) | Git-first (Repo-as-Agent) | Gateway-first (Real-time) | Hardware-first |
| Memory Mgmt | Ultra-lean (<5MB RAM) | Docker Containers (Ephemeral) | Persistent Node.js Process | Native Hardware Layer |
| Audit Trail | High (Sandboxed workspaces) | Maximum (Every thought is a commit) | Medium (JSON/Text logs) | Low (Terminal output) |
| Self-Evolution | Deterministic updates via Rust | PR-based (Human-in-the-loop) | Skill Marketplace (ClawHub) | Manual Scripting |
| Best Use Case | Sovereign Node Images / 24/7 Uptime | Handling Complex Workflows | Rapid Prototyping | GPIO & Physical Triggers |
Concrete comparison (practical checklist)
Use this matrix to decide what to run on the Pi itself vs. offload.
- Real-time GPIO / hardware triggers → On-Pi runner (Rust / static binary)
- Short text classification or local prompt filtering → Quantized tiny model (Ollama/local LLM) if privacy is critical
- Complex planning, long code generation, or heavy chain-of-thought tasks → Cloud models (Anthropic / OpenAI) via orchestrator PR flow
- Self-evolution and skill updates → PR / GitOps process (human-reviewed) — never auto-apply arbitrary code without a safety gate.
The kheAI hybrid blueprint (my tested design)
This is the pattern I run on a Pi 4B (8 GB). It minimizes exposure while preserving speed and autonomy.
Components
- Runner (on Pi) — a tiny Rust binary (deterministic, < 50 MB resident, config-driven). Responsibilities:
- Read local sensors / watch Nostr relays / handle GPIO.
- Execute deterministic scripts and small state machines.
- Pull vetted configuration and skills from Git when approved.
- Orchestrator (GitOps brain) — a GitHub-backed system that:
- Accepts high-level intents (via Telegram / Web UI).
- Writes branches/PRs containing skill proposals.
- Runs ephemeral Docker jobs to validate/execute skills in sandbox. (This is the PopeBot approach.)
- Model layer
- Local LLMs (Ollama / quantized models) for private filtering and short summaries.
- Cloud LLMs (Anthropic / OpenAI) for heavy planning or code gen; called from ephemeral jobs only after human approval or from restricted, audited workflows.
- Storage
- SQLite (local) for checkpoints and idempotency; backups pushed to a remote store.
- Minimal vector store on disk (SQLite + small embedding index) — prune aggressively.
Flow (typical event)
- Runner sees a GPIO event (e.g., a tip on Nostr).
- Runner applies local filter (deterministic rule). If simple, it acts immediately.
- If complex (e.g., “should we publish a payment-driven post?”), the runner signals the Orchestrator: create PR with proposed code/skill.
- Human reviews the PR → merges → GitHub Action spins ephemeral job to run validated code; runner pulls the updated config/skill.
This keeps the Pi as the high-speed reflex layer and the GitOps system as the slow, reflective brain.
Safety, cost control, and “not going broke” rules (operational)
Make these non-optional policies:
- No direct code write access — the agent may propose code (PR) but cannot merge production code unless explicitly authorized for a narrow scope. Use branch protection and required reviews.
- Scoped credentials — create personal access tokens limited to specific repositories or bases (Airtable, Google Drive). Use short TTLs and rotation.
- Billing caps & rate checks — put spending alarms on cloud APIs (Anthropic/OpenAI) and guardrails in orchestrator jobs that abort on >X API calls.
- Ephemeral execution — run every untrusted skill inside a container with memory/cpu limits and no host mounts. After the job ends, destroy the container and its secrets.
- Audit trail — every capability change is a commit/PR with diffs and CI logs — roll back via
git revertif needed.
Phase rollout for kheAI (practical, stepwise)
A phased rollout reduces risk and lets you collect operational telemetry.
- Phase 0 (Manual) — Agent can propose skills only. Human merges. Verify logs and run tests. Good for onboarding.
- Phase 1 (Semi-auto) — Agent can auto-merge non-executable docs and metadata. Code changes still require human merges. Start limited auto-merge for trivial config changes (read-only metadata).
- Phase 2 (Vetted autonomy) — Agent may auto-merge only from a private, audited “skills” repo (signed commits, approved authors). Use lightweight canaries (a single Pi test runner) before fleet rollout.
Pi operational checklist & commands (practical)
- Attach external SSD and mount to
/var/lib/kheai. Put SQLite + vector indexes there. - Enable zram:
sudo apt update && sudo apt install zram-tools
sudo systemctl enable --now zram-swap- Docker container limits (example):
docker run --rm --memory=512m --cpus=".5" --pids-limit=100 ...- Supervisor: use
systemdfor the Rust binary, notpm2for long-running Node daemons.
Reality check: cloud model economics & vendor notes
- Cloud agents & operator products are excellent for rapid capability but read their pricing models: many use consumption-based billing with a mixture of per-token and per-context pricing; model cost can vary significantly by provider and model family. Make sure to set usage quotas and alarms.
- LangChain / LangSmith and comparable observability tools offer paid tiers for tracing and production support; these are useful once you move beyond a single-user Pi lab.
Benchmarks & expected behavior on Pi 4B (8GB)
- Rust runner idle memory: a few MBs → reliable 24/7 operation.
- Local LLM tasks (quantized tiny models) — expect 1–2s latency for short prompts but limited capability for complex code generation.
- Ephemeral Docker job cold start: 15–45s depending on image size and GitHub Action runner (if you use hosted runners). Using self-hosted runners reduces latency but exposes the host unless sandboxed.
Final verdict
- If you want a resilient, low-maintenance, always-on node → build a Rust runner on the Pi and keep heavy reasoning off-device.
- If you want safety and auditability → adopt a GitOps brain (PRs for skills, ephemeral jobs for execution). The PopeBot pattern is a proven fit: repo = memory; PR = permission.
- If you prefer raw iteration speed & lots of integrations → a Node/Python resident agent (OpenClaw-style) will get you there fast, but plan restarts and memory containment on the Pi.
- Reality: hybrid is best. Use the Pi for reflexes, GitOps for reflection.
Your competitive advantage is now purely architectural.
- Choose OpenClaw if: You need a “Jarvis” for a AI Employee right now. Its ClawHub integrations save weeks of coding. If you set up a cron job to restart the process daily and clear the cache, the Pi 4B handles it just fine.
- Choose ZeroClaw if: You are building a true “set-it-and-forget-it” sovereign node. If maximum hardware efficiency and zero bloat are your goals, Rust is the only answer.
- Choose The PopeBot if: If you want to sleep at night knowing your agent cannot rewrite its own security protocols without leaving a
git committhat you can instantly revert, GitOps is mandatory.
For a production-grade kheAI deployment, don’t choose just one. I Use a Hybrid Architecture:
- The Runner (ZeroClaw): A lean Rust binary that sits on the Raspberry Pi, monitoring Nostr relays or local hardware sensors. It has zero “creative” power but handles high-speed execution.
- The Orchestrator (PopeBot): When the Runner hits a complex problem, it triggers a PopeBot Docker Job. PopeBot “thinks,” writes a new configuration or “skill” to Git, and the Runner pulls the update.
This is the Web 4.0 blueprint: A fast “nervous system” (Rust) governed by a reflective, auditable “brain” (GitOps).